Le routage sur Internet : RIP et OSPF
Présentation
Internet est par définition même l'interconnexion de multiples réseaux. Lorsque l'on utilise un navigateur web pour accéder à un contenu, celui ci peut être hébergé de l'autre côté de la planète. Notre requête va traverser un certain nombre d'équipements pour au final arriver sur le serveur que nous souhaitons atteindre. C'est le rôle de la couche IP de gérer ce voyage de données. Ce processus est appelé le routage des données.
Quelques définitions
- Un routeur est une machine qui possède au moins deux connexions à des réseaux distincts, et qui permet de faire transiter des paquets d'un réseau vers un autre.
- On distingue parfois les routeurs d'accès qui sont reliés aux clients et aux serveurs d'un réseau local et les routeurs internes qui sont connectés entre eux et font circuler des paquets dans le cœur du réseau.
- Les équipements possédent une table de routage, qui est une correspondance entre les réseaux de destination et les équipements et interface par lesquels faire transiter les datagrammes IP. Sur un client, la table de routage est en général très simple : elle se limite à indiquer le réseau local auquel on accède par la carte réseau, et la passerelle par défaut qui permet d'accéder à tous les autres réseaux. sur un routeur, la table de routage pourra être bien plus complexe.
Exemple
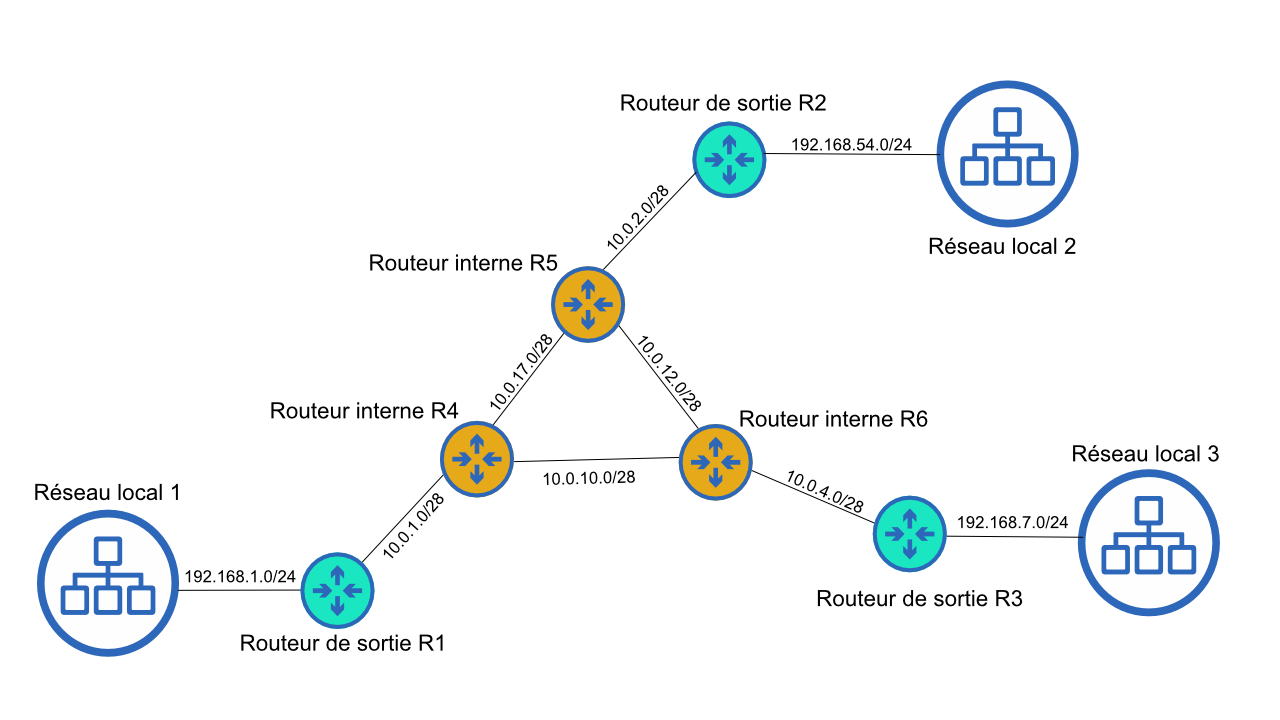
Voici un exemple simplifié de réseau répartie. On a 3 réseaux locaux qui sont reliés à l'extérieur par 3 routeurs de sorties. Il y a aussi 3 routeurs internes reliés à ces routeurs de sortie et éventuellement à d'autres routeurs qui ne figurent pas sur le schéma. Les réseaux ont chacun des plages d'adresse IP indiquées sur le schéma.
L'algorithme de routage
Mais de quelle façon un paquet qui part de notre machine peut il trouver son chemin jusqu'à l'autre bout du monde ? Comment cette information est elle traitée ? Diffusée ? C'est le rôle du routage. Déterminer le chemin. Du point de vue de la machine, elle se sert de la table de routage en appliquant un algorithme assez simple :
- Si la destination est sur le réseau local, on envoie le datagramme sur l'interface réseau qui convient
- Si on a une route vers la destination dans la table de routage, on envoie le datagramme vers le routeur correspondant (qui est donc nécessairement un voisin)
- Sinon, on envoie le datagramme sur le routeur par défaut.
- S'il n'y a pas de route enregistré et pas de routeur par défaut, on retourne une erreur à l'émetteur du datagramme.
La question qui reste en suspend est donc la suivante : comment sont fabriquées ces tables de routage ?
Les protocoles de routage
Routage statique
Commençons par le cas le plus simple. Lorsque l'on est sur une machine implantée dans un réseau local, ou sur un routeur de sortie où il n'y a qu'une ou deux interfaces réseau, et un routeur par défaut disponible, la table de routage est définie à partir des informations obtenues au moment de l'installation de la machine. La table de routage est fixée initialement. On parle alors de routage statique.
Le routage statique est pratique pour des petits réseaux qui ne contiennent que quelques routeurs, mais il devient vite inutilisable dans un réseau de grande taille, géré par plusieurs acteurs et dont la topologie peut changer au fur et à mesure. En effet, un routage statique demande, lorsque l'on ajoute un routeur ou lorsqu'un routeur tombe en panne, à ce qu'une intervention humaine ait lieu pour modifier les tables de routage. Cela n'est pas gérable à grande échelle.
On délègue donc au retour le soin de construire eux même les tables de routage. En plus de se transmettre des paquets, les routeurs vont échanger des informations sur les routes à leur disposition et l'état des connexions. L'échange de ces informations suit un certain nombre de règle que l'on appelle un protocole de routage. Il y en a aujourd'hui principalement deux types :
- Le routage dit "à vecteur de distance" avec le protocole RIP
- Le routage à "état de lien" avec le protocole OSPF
La vidéo de Claude CHAUDET suivante introduit bien cette notion de routage dynamique par opposition au routage statique en rappelant les fondamentaux sur le routage interne (c'est à dire entre les routeurs qui constituent le cœur d'internet).
Le protocole RIP
Le protocole RIP ( Routing Information Protocol ) date de la fin des années 1980. Il a été l'un des premiers protocoles utilisé pour configurer automatiquement les routeurs sur internet. Il repose sur un principe assez simple qui assure sa robustesse. Périodiquement,(toutes les 30 secondes le plus souvent), chaque routeur échange avec ses voisins la table de routage qu'il possède. Chaque routeur ne communique qu'avec son voisin, mais la table de routage se construit au fur et à mesure. Les routeurs ne vont pas chercher l'information : c'est l'information qui vient à eux et se "répand" au fur et à mesure.
Les tables de routages contiennent les informations suivantes :
- Le réseau de destination
- La passerelle pour y accédere
- La distance de ce réseau (qui est le nombre de sauts)
Lorsqu'un routeur reçoit de son voisin les tables de routage, il les analyse et applique l'algorithme suivant :
- si une destination transmise par le voisin est inconnue, alors elle est ajoutée à la table du routage en ajoutant 1 à la distance transmise par le voisin. C'est le voisin qui a transmis cette nouvelle route qui est indiqué comme passerelle (c'est vers lui que l'on enverra le paquet à destination de ce réseau).
-
Si une destination transmise par le voisin est déjà connue, on distingue pmusieurs cas. :
- Si le passage par cette route est plus avantageux, la table de routage est mise à jour.
- Si le passage par cette route est du même coût ou plus élevé sans provenir du routeur actuel, il est ignoré
- Si le passage par cette route est d'un coût plus élevé et provient du routeur actuellement dans la table de routage, c'est qu'il y a eu une modification sur la structure du réseau et la table de routage doit être mise à jour.
La mise en œuvre de ce protocole est très bien décrite dans ce cours de Claude CHAUDET (Institut Mines Télécom)
Exemple
Considérons le réseau suivant qui relie deux réseaux d'une entreprise :
- le réseau 1 contient des postes de travail dans un bureau.
- le réseau 2 contient un serveur dans un centre de données.
Les routeurs R1 et R6 permettent d'accéder au réseau de l'entreprise, R2, R3, R4 et R5, des routeurs internes au réseau. schéma
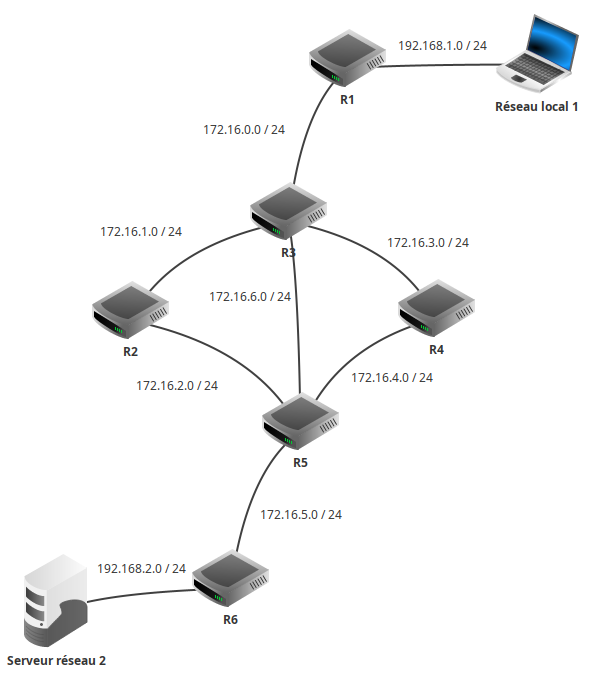
Nous allons nous intéresser à l'évolution des tables de routage des routeurs R1 et R3 sur lesquels on a activé le protocole RIP.
Étape 0
Au démarrage, les routeurs R1 et R3 ne connaissent que leurs voisins proches. Leurs tables peuvent donc ressembler à ceci :
| destination | passerelle | interface | Nb sauts | remarques |
|---|---|---|---|---|
| 192.168.1.0/24 | wifi0 | 1 | ==> vers les postes de travail | |
| 172.16.0.0/24 | eth0 | 1 | ==> vers R3 |
Au départ, R1 ne peut atteindre que ses voisins immédiats (nb Sauts vaut 1). Aucune passerelle n'est nécessaire puisque la communication est directe. Chaque sous réseau utilise une interface spécifique. Le réseau local 1 contenant les postes de travail est accessible en wifi.
En ce qui concerne le routeur 3, celui-ci possède 4 interfaces réseau filaires, que nous nommerons eth0-3 qui permettent d'atteindre les routeurs immédiats (R1, R2, R4 et R5). Voici à quoi peut ressembler sa table de routage au démarrage :
| destination | passerelle | interface | Nb sauts | remarques |
|---|---|---|---|---|
| 172.16.0.0/24 | eth0 | 1 | ==> vers R1 | |
| 172.16.1.0/24 | eth1 | 1 | ==> vers R2 | |
| 172.16.2.0/24 | eth2 | 1 | ==> vers R5 | |
| 172.16.3.0/24 | eth3 | 1 | ==> vers R4 |
Étape 1
Au bout de 30 secondes, un premier échange intervient avec les voisins immédiats de chacun des routeurs. Il applique l'algorithme vu précédemment. En appliquant ces règles, voici la table de routage de R1 après une étape :
| destination | passerelle | interface | Nb sauts | remarques |
|---|---|---|---|---|
| 192.168.1.0/24 | wifi0 | 1 | ==> vers les postes de travail | |
| 172.16.0.0/24 | eth0 | 1 | ==> vers R3 | |
| 172.16.1.0/24 | 172.16.0.3 | eth0 | 2 | ==> ces trois routes passent par R3 |
| 172.16.6.0/24 | 172.16.0.3 | eth0 | 2 | |
| 172.16.3.0/24 | 172.16.0.3 | eth0 | 2 |
On a ajouté à la table précédente les réseaux atteignables par R3. On pense cependant à ajouter 1 au nombre de sauts ! Si R1 veut atteindre le réseau 172.16.3.0, il s'adressera à R3 et atteindra le réseau cible en 2 sauts.
Voici la table de R3 qui s'enrichit des informations envoyées par R1 afin d'atteindre le réseau local, mais aussi des informations en provenance de R2, R4 et R5. Il découvre ainsi 4 nouveaux réseaux.
| destination | passerelle | interface | Nb sauts | remarques |
|---|---|---|---|---|
| 172.16.0./24 | eth0 | 1 | ||
| 172.16.1.0/24 | eth1 | 1 | ||
| 172.16.6.0/24 | eth2 | 1 | ||
| 172.16.3.0/24 | eth3 | 1 | ||
| 192.168.1.0/24 | 172.16.0.1 | eth0 | 2 | reçu de R1 |
| 172.16.2.0/24 | 172.16.1.2 | eth1 | 2 | reçu de R2 |
| 172.16.5.0/24 | 172.16.6.5 | eth2 | 2 | reçu de R5 |
| 172.16.4.0/24 | 172.16.3.4 | eth3 | 2 | reçu de R4 |
Étape 3
Comme vous le voyez, les tables deviennent vite longues et énumérer dans le détail chacune d'elle est trop long. On va donc passer directement à l'étape finale : l'étape 3. Voici ce que contient la table de routage de R1 :
| destination | passerelle | interface | Nb sauts | remarques |
|---|---|---|---|---|
| 192.168.1.0/24 | wifi0 | 1 | ==> vers les postes de travail | |
| 172.16.0.0/24 | eth0 | 1 | ==> vers R3 | |
| 172.16.1.0/24 | 172.16.0.3 | eth0 | 2 | |
| 172.16.6.0/24 | 172.16.0.3 | eth0 | 2 | |
| 172.16.3.0/24 | 172.16.0.3 | eth0 | 2 | |
| 172.16.5.0/24 | 172.16.0.3 | eth0 | 3 | obtenu à l'étape 2 |
| 192.168.2.0/24 | 172.16.0.3 | eth0 | 4 | obtenu à l'étape 3 |
Comme vous le voyez, le routeur R1 est à présent en capacité d'acheminer un paquet du poste de travail du réseau 1 vers le serveur se trouvant dans le réseau 2.
Le protocole RIP fonctionne bien, mais il présente un certain nombre d'inconvénients. Outre le caractère "verbeux" de ce protocole où les informations doivent être transmises et analysées toutes les 30 secondes, il n'y a aucune garantie sur la qualité de service. En effet, seul le nombre de sauts est analysé et il n'y a aucune prise en compte de la bande passante des différentes liaisons. Par ailleurs, dans le protocole RIP, on limite le nombre de sauts à 15, pour éviter les boucles et les parcours trop longs. Cela limite la taille du réseau qui peut être géré de cette façon.
Le protocole OSPF
Pour pallier ces insuffisance, le protocole OSPF (Open Shortest Path First) a été élaboré. Le protocole RIP est dit à vecteur de distance. Le protocole OSPF va prendre en compte la qualité des liaisons et on parle de protocole à état de lien.
Le protocole OSPF propose une approche tout à fait différente : au lieu de s'intéresser au nombre de sauts, on va chercher à optimiser le débit des liaisons empruntées. Pour cela, chaque routeur va devoir connaître l'intégralité du réseau avec le débit associé à chaque lien afin d'appliquer un algorithme de recherche de chemin optimal.
On peut faire un parallèle entre le fonctionnement d'OSPF et celui de nos logiciels de guidage par GPS. En effet, dans ce type de logiciels :
- l'ensemble de la carte de France et de ses routes est connue du logiciel
- le type de chaque route est renseigné ainsi que la vitesse autorisée sur la route
- le calcul d'itinéraire va permettre le calcul d'un chemin permettant par exemple d'emprunter les routes sur lesquelles la vitesse est la plus importante (temps le plus court).
Cette vidéo de Claude CHAUDET (Institut Mines-Télécom) expose le principe du routage à état de lien, comme OSPF.
Nous n'entrerons pas dans le détail technique de l'algorithme de Djikstra lié au protocole OSPF. Ce qu'il faut retenir, c'est que l'on affecte un "coût" ou un poids à chaque liaison, inversement proportionnel au débit, et que le protocole va déterminer le chemin le moins couteux pour aller d'un point à un autre du réseau.
Le protocole BGP
Comme nous l'avons vu précedemment, pour des raisons différentes, les protocoles de routage RIP et OSPF qui ont été développé dans les années 80 au moment de la construction d'internet, ne permettent pas de gérer des réseaux qui contiendrait des dizaines de millier voire des millions de routeur. Mais au fur et à mesure que l'internet grandissait, une autre problématique a vu le jour avec une multiplication des acteurs et des opérateurs de réseau.
Les réseaux des grands opérateurs sont des zones autonomes de service. Au sein de ces zones, le routage est géré au moyen des protocoles RIP ou OSPF.
La liaison entre les différentes zones de service est gérée au moyen du protocole BGP ( Border Gateway Protocol ) qui prend en compte des caractéristiques physiques mais qui permet aussi de gérer différents types d'accords commerciaux. Il limite la taille des tables de routage, permet la décentralisation du routage sur internet, et il masque la topologie interne des Autonomous System. L'étude de ce protocole est en dehors du programme d'informatique du lycée.
Remarque
Si vous voulez aller plus loin, vous pouvez consulter le cours sur les réseaux de "Zeste de savoir", en particulier pour cette page, la partie sur le routage
En résumé
- Le routage sur internet permet de trouver le chemin pour qu'un paquet aille d'un client à un serveur et réciproquement
- Chaque machine, même une imprimante ou une box internet, dispose d'une table de routage qui lui permet de déterminer quel chemin prendre pour envoyer un paquet.
- Le routage le plus simple est le routage statique où la table est construite à l'installation du système et n'évolue que par une intervention humaine
- Le routage RIP est un routage à vecteur de distance qui compte uniquement le nombre d'étapes (saut, ou hop en anglais) pour arriver à destination. Il convient pour les petits réseaux.
- Le routage OSPF prend en charge les caractéristiques des connexions et la bande passante. C'est un routage à état de liens. Il convient pour les réseaux de taille plus importante.
- Sur internet, le réseau est découpé en zone autonomes qui gère chacune leur routage par RIP ou OSPF. La communication entre ces zones est gérée au moyen du protocole BGP.